

 首页
首页 关于我们
关于我们 产品中心
产品中心 技术服务
技术服务 技术中心
技术中心 联系我们
联系我们
导读
表征蛋白质编码基因组是研究人类健康的基础,也是一项重大的科学目标。蛋白质编码基因是生物医学研究的基石,绝大多数药物开发项目都以此为基础。
然而,人类基因组是否编码了远超约19500个经典蛋白质编码基因一直存在激烈争论。近十年来,科学家们在多种人类细胞类型和疾病状态下观察到非经典开放阅读框(ncORFs)的翻译现象。
这些翻译产物,如微蛋白或小肽,被认为是“暗蛋白质组”的一部分。尽管它们在疾病的遗传基础、癌症生物学机制和免疫治疗靶点等方面显示出巨大潜力,但由于缺乏明确的功能和进化保守性证据,绝大多数尚未被权威数据库注释为真正的蛋白质。
2026年5月6日,由多个国际研究机构组成的TransCODE联合会在Nature上发表了题为“Expanding the human proteome with microproteins and peptideins”的重磅论文。该研究通过对海量蛋白质组学数据的系统性分析,发现约25%的已知ncORFs能够产生可被检测到的肽段,并以此为基础建立了一套标准化的注释框架。

文章索引
【标题】Expanding the human proteome with microproteins and peptideins
【发表期刊】Nature
【发表日期】2026年5月6日
【作者及团队】TransCODE Consortium (Sebastiaan van Heesch,John R. Prensner, Robert L. Moritz等领衔)
【IF】48.5
研究结果
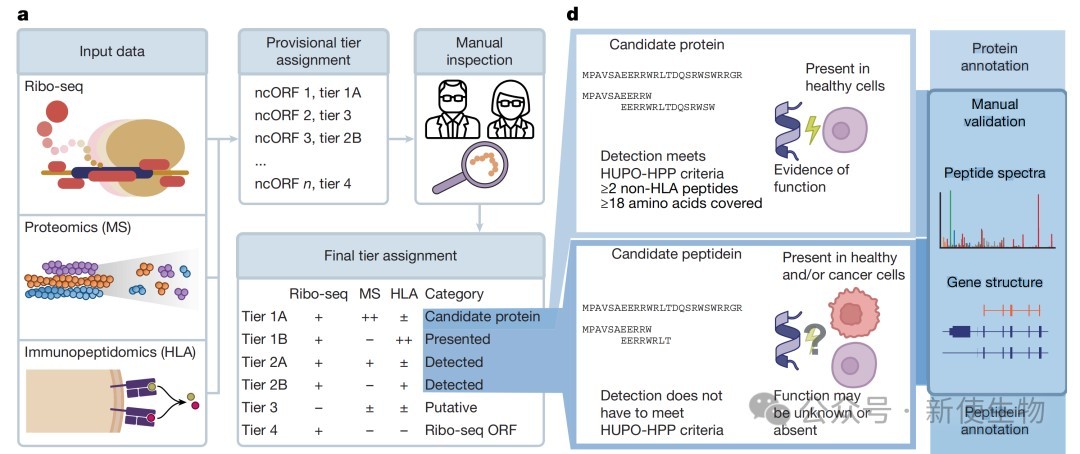
一、构建基于PeptideAtlas的微蛋白鉴定与注释标准化工作流
研究团队整合了海量的非HLA酶解质谱数据和HLA免疫肽段组数据,利用高标准的蛋白水平假阳性率(FDR < 0.1%)过滤逻辑,建立了一套严谨的微蛋白鉴定体系。
该流程旨在为GENCODE等参考注释机构提供高质量的蛋白质证据支持,确保ncORF从转录本层面的发现跨越到蛋白质层面的验证。
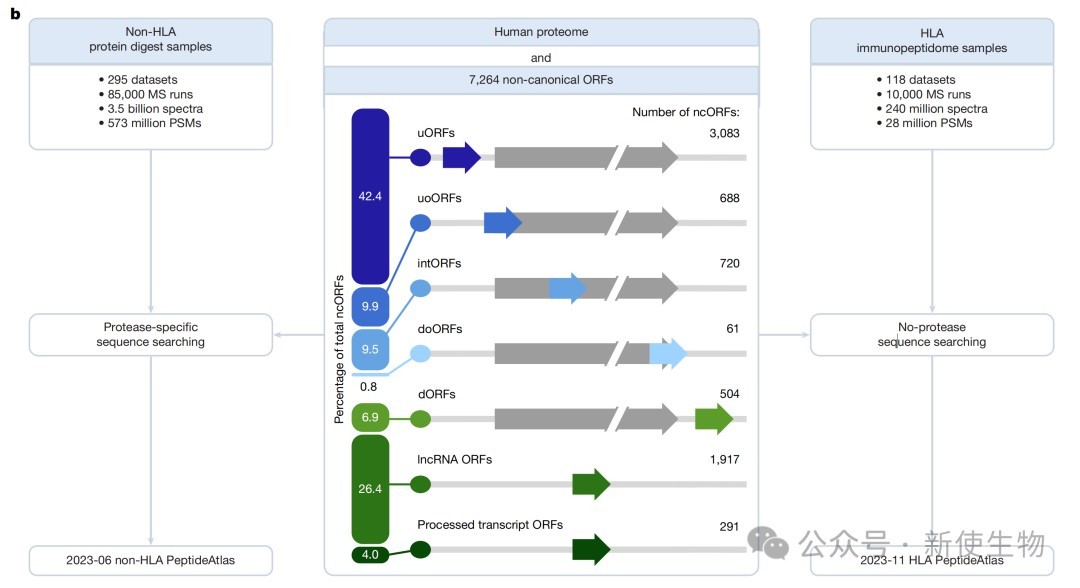
二、利用大规模质谱数据验证ncORF编码产物的内源性表达
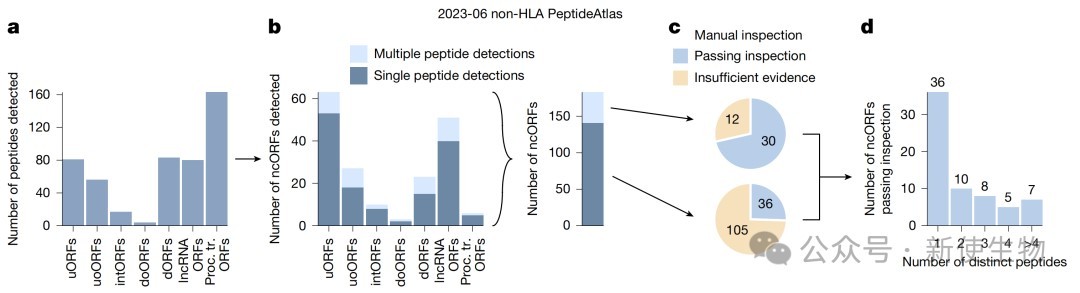
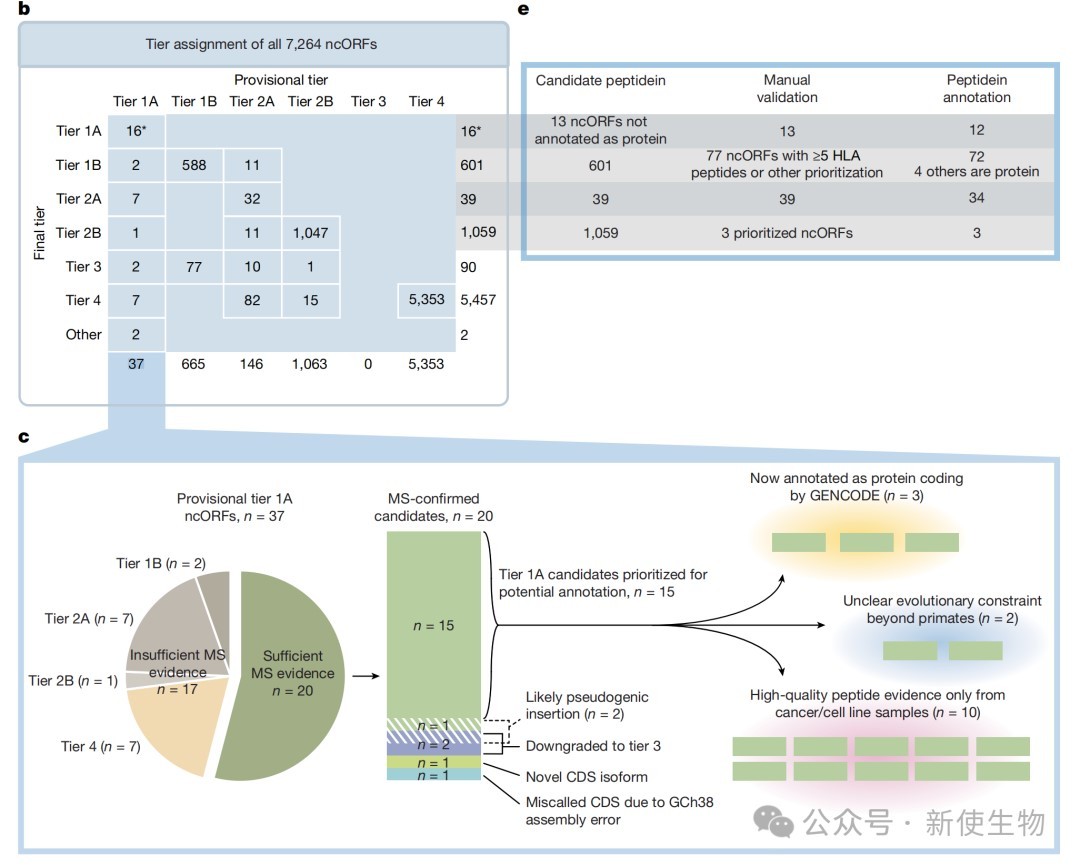
通过对35亿个非HLA质谱光谱进行检索,研究人员在183个ncORFs中发现了符合要求的肽段证据,并通过人工检查光谱、合成肽段比对以及Ribo-seq核糖体印迹分析进行了严格校验。
实验结果显示,虽然由于体积微小导致常规质谱检测率较低,但仍有30个ncORFs达到了HUPO-HPP的蛋白验证基准。
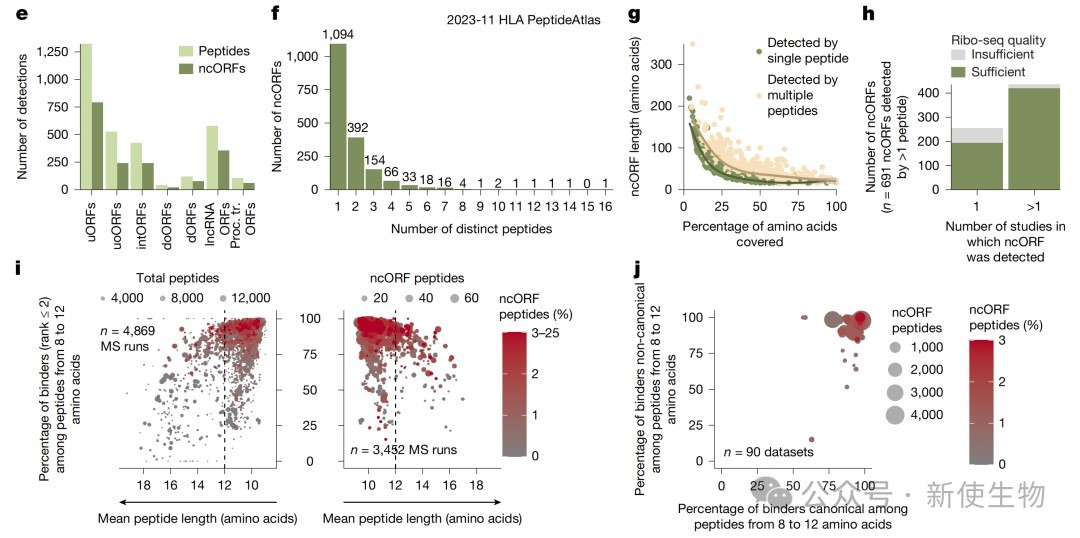
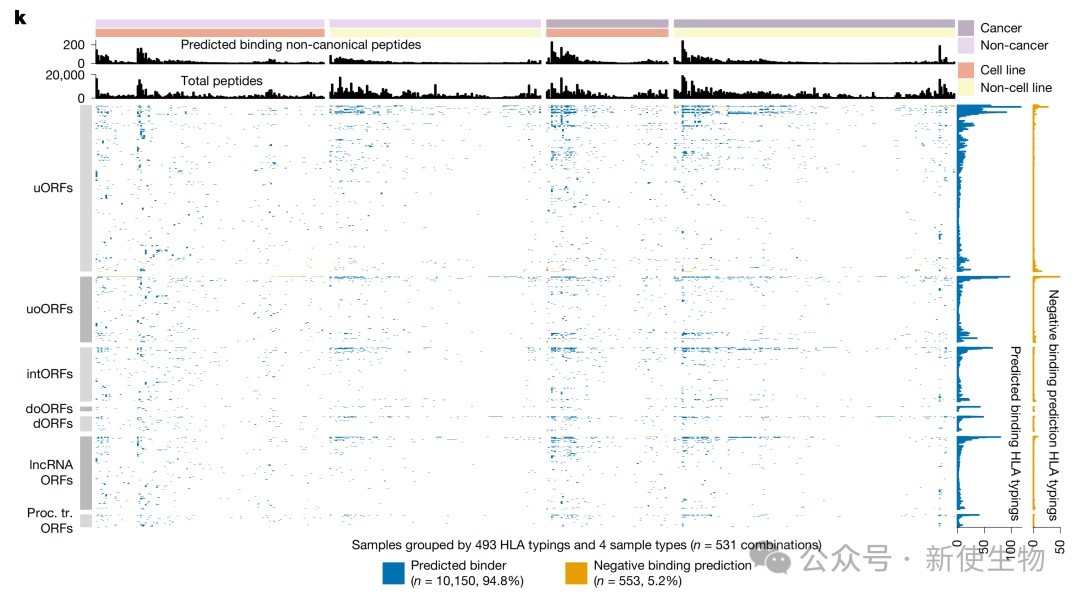
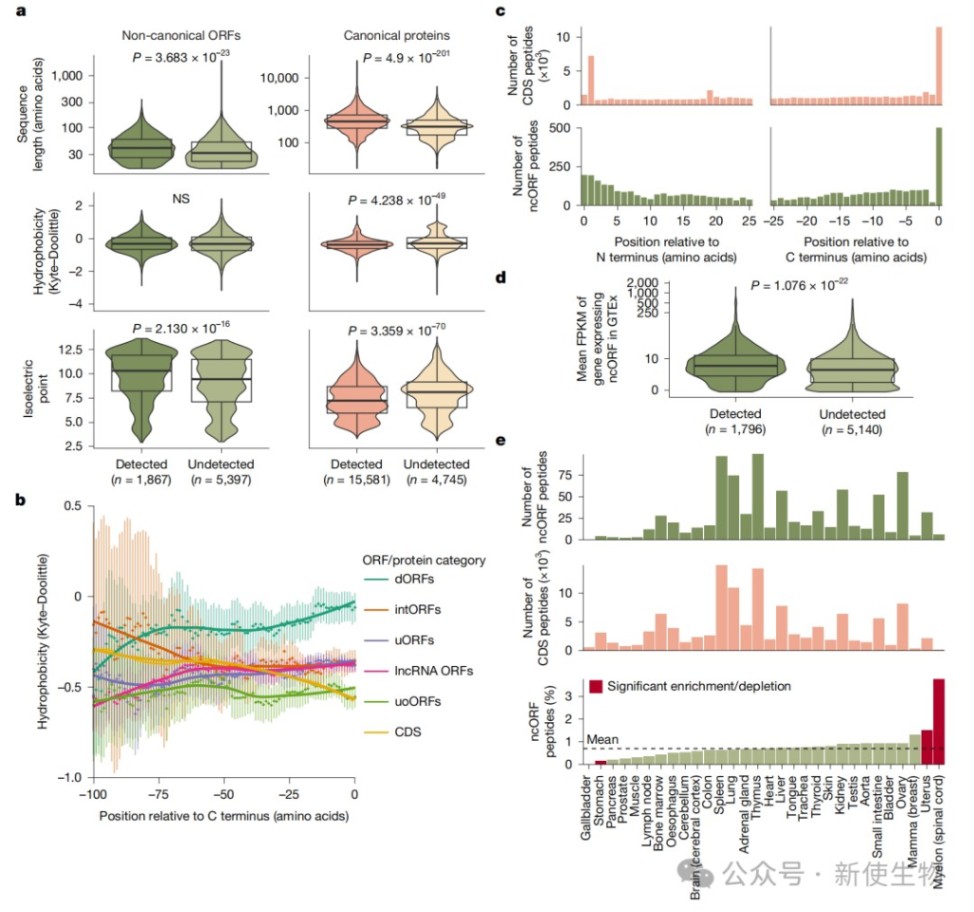
三、揭示微蛋白在HLA-I类分子呈现中的普遍性及其生化特征
研究发现大量微蛋白倾向于通过HLA-I类途径呈递,在7,264个ncORFs中鉴定出3,116个HLA肽段,覆盖了24.6%的候选框。
生化分析表明,被检测到的微蛋白具有更高的等电点且更倾向于从其C末端产生肽段,这为理解微蛋白的胞内加工提供了重要线索。
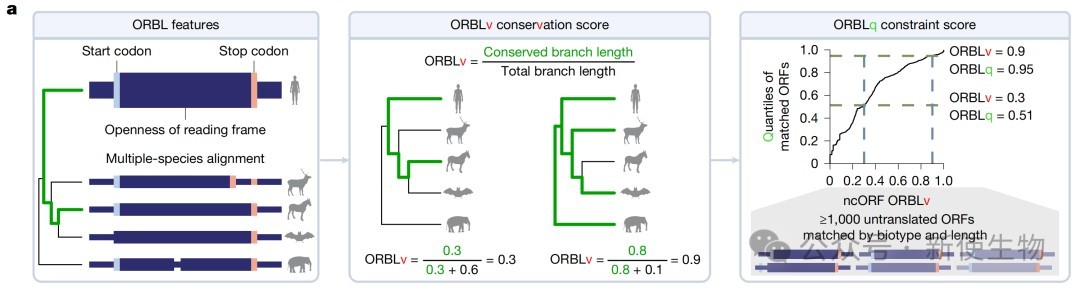
四、开发ORBL工具评估ncORF的演化约束力
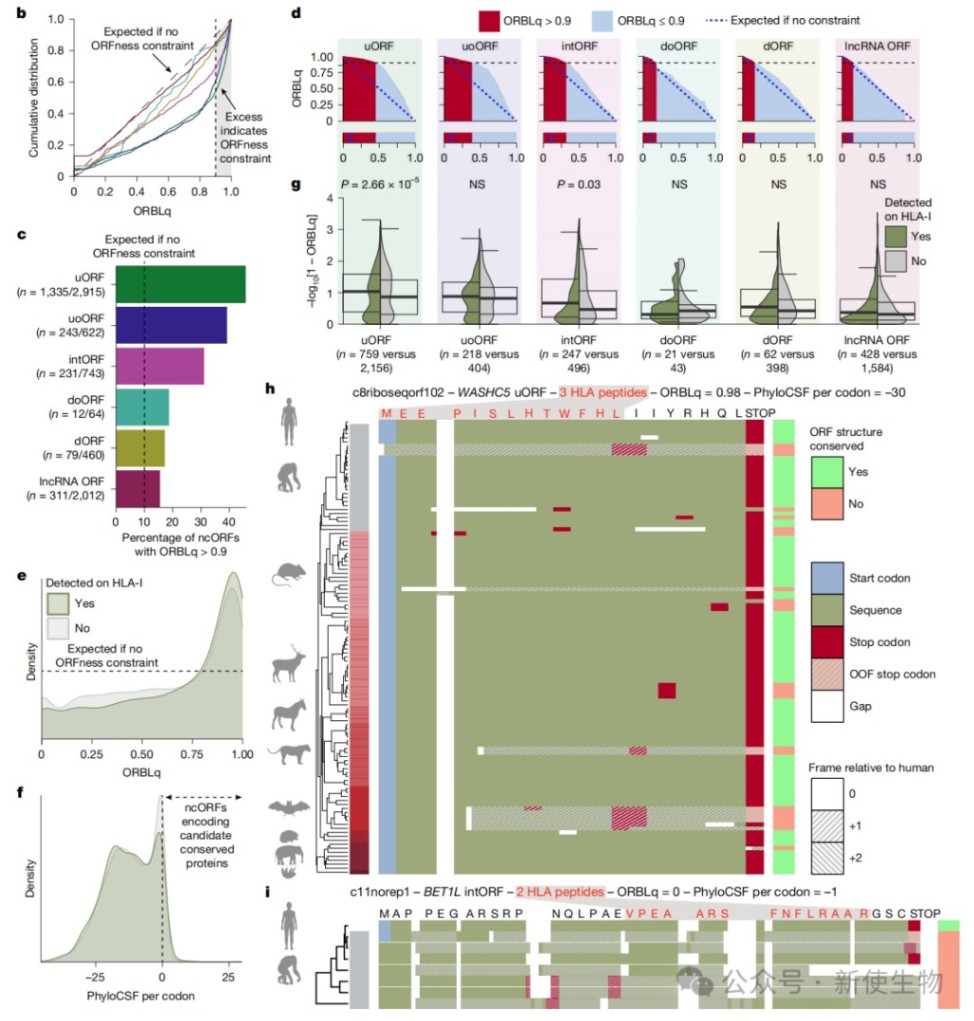
为了突破传统氨基酸序列守恒性分析的局限,研究者创建了ORF相对分支长度(ORBL)算法,通过衡量开放阅读框结构的守恒性来评估其功能潜力。
分析显示,超过30%的ncORFs表现出显著的演化约束力,且这种约束力与肽段的可检测性呈正相关。
五、建立微蛋白分层注释系统并定义“Peptidein”概念
研究根据质谱证据的质量、Ribo-seq核糖体印迹分析及演化特征,将ncORFs分为四个等级,并正式引入“peptidein”这一分类,指代那些已有实验证实表达、但尚未达到常规蛋白质功能证据标准的产物。
这一系统成功推动了15个候选产物向常规蛋白质注释的转化。
六、整合功能基因组学筛选鉴定必需的peptidein成员
通过整合多中心CRISPR-Cas9筛选数据与单细胞转录组分析,研究鉴定出51个具有泛必需表型的ncORFs,并重点解析了OLMALINC转录本产生的一个123氨基酸微蛋白。
实验证实该微蛋白对癌症细胞的存活至关重要,其缺失会诱发细胞有丝分裂及DNA损伤修复过程的紊乱。
总结
本研究通过多学科协作,为人类基因组中被忽视的非典型开放阅读框提供了系统性的注释框架,并引入了“peptidein”这一分类以填补蛋白质组学研究的空白。该工作不仅扩展了人类蛋白质组的边界,也为未来针对微蛋白的生物医学发现及癌症免疫治疗提供了坚实的理论与数据基础。
| 新使生物专业翻译组一站式服务平台 |
| 产品名称 |

点击图片查看
点击图片查看